PGQueuer for High-Performance Job Queues
PGQueuer takes a PostgreSQL database and can turn it into a reliable background job processor. The problem becomes how on the face unwieldy the technology is. Because it’s powerful, it requires a lot to get into, especially for people new to backend development.
We will have one main entrypoint file that will handle jobs:
from datetime import datetime
import asyncpg
from pgqueuer import PgQueuer
from pgqueuer.db import AsyncpgDriver
from pgqueuer.models import Job, Schedule
async def main() -> None:
conn = await asyncpg.connect()
driver = AsyncpgDriver(conn)
pgq = PgQueuer(driver)
@pgq.entrypoint("fetch")
async def process(job: Job) -> None:
print(f"Processed: {job!r}")
return pgq
if __name__ == "__main__":
import asyncio
asyncio.run(main())
This is our consumer. The consumer has workers under its control that it will asynchronously divy tasks to. All tasks are stored on a backend postgre table that generates in your environment.
Below is what this main table looks like:
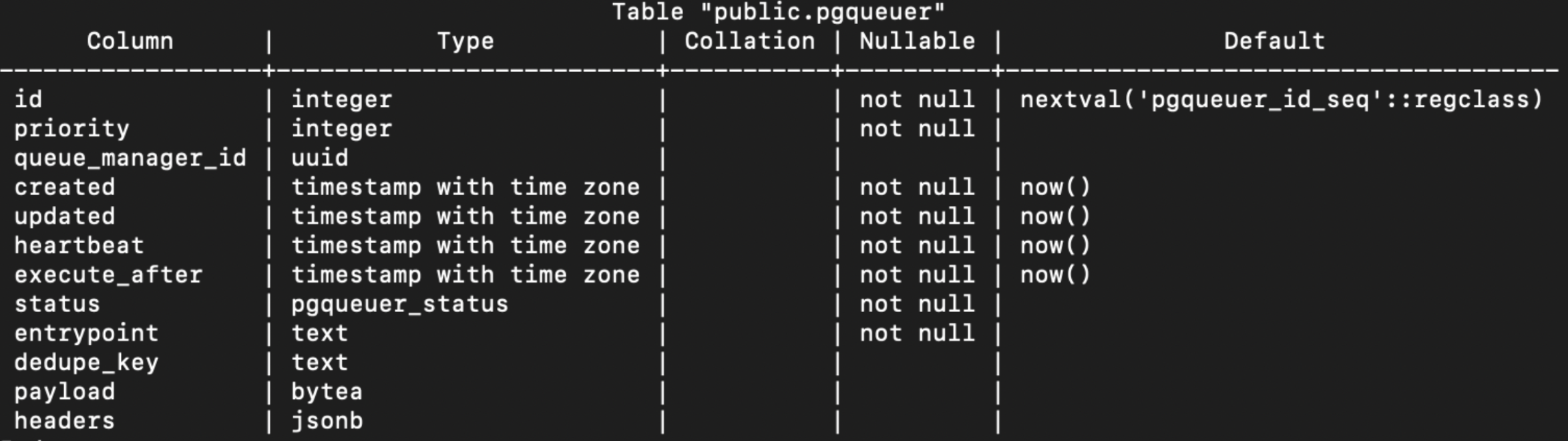
A lot of these entries are for under the hood functionality that makes graciously failing tasks, auditing and proper scheduling efficient, but we only need to worry about a few pieces.
The entrypoint text directs us to what function should be ran. The payload is a deconstructed json object that gives the function the necessary parameters to run the job. Lastly priority describes the numerical agency of the task.
We run our code above using “pgq run consumer:main”. And it’s time we send a job!
Entrypoint: fetch
Payload: hello world
Priority: 0 (lowest)
import asyncpg
from pgqueuer.db import AsyncpgDriver
from pgqueuer.queries import Queries
async def main() -> None:
conn = await asyncpg.connect()
driver = AsyncpgDriver(conn)
q = Queries(driver)
# Enqueue a job for the "fetch" entrypoint
await q.enqueue(["fetch"], [b"hello world"], [0])
print("Job enqueued!")
await conn.close()
if __name__ == "__main__":
import asyncio
asyncio.run(main())
Our q.enqueue line does all the desired work, and on our backend we get the job as desired! Here’s the issue, I want more complex statuses and jobs to be ran that are staged in multiple parts. So, in order to circumvent this, I personally created another table to reference in my payloads to handle the more complex jobs needed.
There are more complex topics to talk about within PgQueuer, however the developers do a sufficient job at hiding a lot of the complexities for more sophisticated operations and detail those in the documentation.